Nächste Seite: 12 Determinante Aufwärts: Mathematik 1 für Informatik Vorherige Seite: 10 Lineare Abbildungen und Inhalt Index
Eine der Hauptaufgaben die an Mathematiker gestellt werden ist das Lösen von Gleichungen, wie z.B.
|
oder allgemein
| |
Wir haben bislang Gleichungen der ersten 3 Arten behandeln. Nun wenden wir uns solchen der 4.ten Art, sogenannten linearen Gleichungen zu.
Um dieses Problem anzugehen, müssen wir uns aus der Physik in Erinnerung
rufen, daß der bei konstanter Geschwindigkeit ![]() in der Zeit
in der Zeit ![]() zurückgelegte Weg gerade
zurückgelegte Weg gerade ![]() ist.
Wir können beide Züge in ein Zeit-Weg Diagramm einzeichnen.
D.h. wir tragen auf der horizontalen Achse die Zeit
ist.
Wir können beide Züge in ein Zeit-Weg Diagramm einzeichnen.
D.h. wir tragen auf der horizontalen Achse die Zeit ![]() (bei 9h beginnend)
und auf der vertikalen Achse den Abstand von
(bei 9h beginnend)
und auf der vertikalen Achse den Abstand von ![]() auf.
auf.
![\includegraphics[scale=0.7]{la-001}](img2866.png)
Zeit und Ort des Treffpunkts können wir dann geometrisch aus den Koordinaten des Schnittpunktes der beiden Geraden ablesen.
Natürlich können wir das auch präzise durchrechnen.
Der Abstand des 1. Zuges von ![]() zum Zeitpunkt
zum Zeitpunkt ![]() ist
ist
![]() und jeder des 2. Zuges von
und jeder des 2. Zuges von ![]() zum Zeitpunkt
zum Zeitpunkt ![]() ist
ist
![]() . Also
ist das Gleichungssystem
. Also
ist das Gleichungssystem
Wir nennen die jeweiligen Stückzahlen ![]() ,
, ![]() und
und ![]() .
Dann läßt sich die Angabe durch folgende 3 Gleichungen beschreiben
.
Dann läßt sich die Angabe durch folgende 3 Gleichungen beschreiben
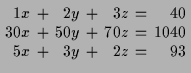
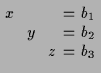
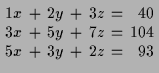
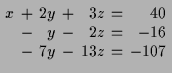
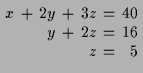
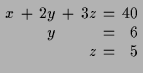
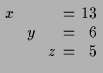
Beispiel.
Ein vorläufig letztes Beispiel aus der Chemie.
Um den Sprengstoff Trinitrotoluol (TNT)
![]() zu gewinnen
wird Methylbenzol (Toluol)
zu gewinnen
wird Methylbenzol (Toluol) ![]() und Salpetersäure
und Salpetersäure ![]() gemischt und man erhält Wasser
gemischt und man erhält Wasser ![]() und
und ![]() .
.
In welchen Mengen reagieren nun die involvierten Substanzen?
Wenn ![]() ,
, ![]() ,
, ![]() und
und ![]() die Molekülanzahlen
der an der Reaktion
die Molekülanzahlen
der an der Reaktion
Das oben beschriebene Verfahren liefert in diesen Fall:
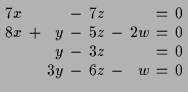
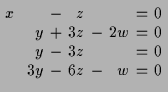
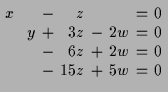
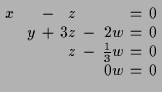
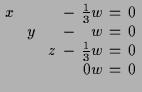
11.2 Geometrische Interpretation.
Wir wollen nun ein (geometrisches) Verständnis für solche
eventuell unendliche Lösungsmengen
![]() linearer Gleichungen
entwickeln.
Die Koeffizienten
linearer Gleichungen
entwickeln.
Die Koeffizienten
![]() der Gleichungen
bilden eine Matrix
der Gleichungen
bilden eine Matrix
![]() , die wir als lineare Abbildung
, die wir als lineare Abbildung
![]() auffassen können.
Die Inhomogenitätsterme
auffassen können.
Die Inhomogenitätsterme
![]() bilden einen Vektor
bilden einen Vektor
![]() und Lösungen
und Lösungen
![]() des linearen Gleichungssystems
sind gerade Punkte
des linearen Gleichungssystems
sind gerade Punkte
![]() mit
mit
![]() , beschreiben also
einen affinen Teilraum von
, beschreiben also
einen affinen Teilraum von
![]() den man dadurch erhält, daß
man zur einer Lösung des inhomogenen Gleichungssystems alle Lösungen
den man dadurch erhält, daß
man zur einer Lösung des inhomogenen Gleichungssystems alle Lösungen
![]() des zugehörigen homogenen Systems
des zugehörigen homogenen Systems
![]() , d.h. den
, d.h. den
![]() hinzuaddiert.
Falls
hinzuaddiert.
Falls
![]() surjektiv oder zumindest
surjektiv oder zumindest
![]() im Bild von
im Bild von
![]() liegt so existiert
mindestens eine Lösung
liegt so existiert
mindestens eine Lösung
![]() von
von
![]() . Ist
. Ist
![]() injektiv so ist die Lösung
eindeutig bestimmt. Ist
injektiv so ist die Lösung
eindeutig bestimmt. Ist
![]() bijektiv, so existiert für jedes
bijektiv, so existiert für jedes
![]() eine eindeutig bestimmte Lösung
eine eindeutig bestimmte Lösung
![]() und diese kannals
und diese kannals
![]() berechnet werden.
berechnet werden.
Es sei
![]() linear. Dann nennt man eine Gleichung
der Form
linear. Dann nennt man eine Gleichung
der Form
![]() eine homogene lineare Gleichung
und eine solche der Form
eine homogene lineare Gleichung
und eine solche der Form
![]() mit gegebenen
mit gegebenen
![]() eine inhomogene
lineare (oder auch affine) Gleichung.
eine inhomogene
lineare (oder auch affine) Gleichung.
Als Resumeé haben wir also:
Proposition.
Die Gesamtheit der Lösungen eines homogenen linearen Gleichungssystems
bilden einen Vektorraum, einen Teilvektorraum von
![]() . []
. []
Sowie:
Proposition.
Die allgemeine Lösung einer inhomogenen linearen Gleichung wird dadurch
beschrieben, daß man zu einer (speziellen) Lösung der inhomogenen Gleichung
alle Lösungen der entsprechenden homogenen Gleichung hinzuaddiert. []
Man rufe sich in diesen Zusammenhang die geometrische Interpretation
einer Gleichung
![]() mit Koeffizienten
mit Koeffizienten
![]() in Erinnerung. Dies beschreibt (im Fall
in Erinnerung. Dies beschreibt (im Fall
![]() ) bekanntlich eine Ebene im Raum,
und mehrere solche Gleichungen, die gleichzeitig erfüllt sein sollen, denn
Durchschnitt der entsprechenden Ebenen, also je nach Anzahl und Lage
eine Ebene, eine Gerade, einen Punkt oder die leere Menge.
Obige Parameterdarstellung der Lösungen des Gleichungssystems nach Gauß
entspricht dabei gerade der Bestimmung einer Parameterdarstellung
dieser Schnittmenge.
) bekanntlich eine Ebene im Raum,
und mehrere solche Gleichungen, die gleichzeitig erfüllt sein sollen, denn
Durchschnitt der entsprechenden Ebenen, also je nach Anzahl und Lage
eine Ebene, eine Gerade, einen Punkt oder die leere Menge.
Obige Parameterdarstellung der Lösungen des Gleichungssystems nach Gauß
entspricht dabei gerade der Bestimmung einer Parameterdarstellung
dieser Schnittmenge.
11.3 Proposition.
Sei
![]() linear und
linear und
![]() fix.
Dann besitzt die Gleichung
fix.
Dann besitzt die Gleichung
![]() genau dann eine Lösung
genau dann eine Lösung
![]() , wenn
, wenn
![]() liegt. Die Menge aller Lösungen ist dann durch
liegt. Die Menge aller Lösungen ist dann durch
![]() gegeben, ist also ein affiner Teilraum der Dimension
gegeben, ist also ein affiner Teilraum der Dimension
![]() .
Die Lösungen von
.
Die Lösungen von
![]() sind dann durch
sind dann durch
![]() gegeben, wobei die
gegeben, wobei die
![]() eine Basis von
eine Basis von
![]() seien.
seien.
11.4 Gauß'sches Eliminationsverfahren.
Wenn wir ein allgemeines inhomogenes lineares Gleichungssystem
in
![]() vielen
Variablen
vielen
Variablen
![]() ,
,
![]() ,
,
![]() und
und
![]() vielen Gleichungen
der Form
vielen Gleichungen
der Form
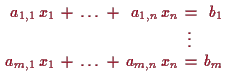

Falls die erste Spalte aus lauter Nullen besteht so machen wir im ersten
Schritt nichts. Andernfalls wählen wir eine
Zeile
![]() deren erster Koeffizienten
deren erster Koeffizienten
![]() ist, multiplizieren diese
mit
ist, multiplizieren diese
mit
![]() um als ersten Koeffizienten 1 zu erhalten, und tauschen sie
an die 1. Stelle. Sodann ziehen wir von allen übrigen Zeilen
um als ersten Koeffizienten 1 zu erhalten, und tauschen sie
an die 1. Stelle. Sodann ziehen wir von allen übrigen Zeilen
![]() das entsprechende Vielfache
das entsprechende Vielfache
![]() der ersten Zeile ab
um alle anderen Koeffizienten der 1. Spalte in 0'en zu verwandeln.
der ersten Zeile ab
um alle anderen Koeffizienten der 1. Spalte in 0'en zu verwandeln.
Im nächsten Schritt verfahren wir ebenso mit der 2. Spalte fort, wobei
wir allerdings die 1. Zeile unverändert stehen lassen
und nur die Zeilen 2 bis
![]() weiter umformen, falls wir bei ihr im
vorangegangenen Schritt schon einen 1'er als ersten Koeffizienten
erreicht haben.
weiter umformen, falls wir bei ihr im
vorangegangenen Schritt schon einen 1'er als ersten Koeffizienten
erreicht haben.
Diese Schritte führen wir solange durch, bis keine Zeilen oder keine
Spalten (bis auf die letzte) mehr übrig sind, wobei wir jeweils jene Zeilen,
in denen wir schon einen führenden 1'er erreicht haben unverändert
abschreiben.
Wenn wir jene Spalten, wo wir einen 1'er erzeugen konnten,
weil sie an den relevanten Stellen nicht aus lauter
0'er bestanden haben, mit
![]() bezeichnen, so haben wir
eine Form erreicht, wo
bezeichnen, so haben wir
eine Form erreicht, wo
![]() für
für
![]() und alle
anderen Eintragungen im Teil-Rechteck,
dessen rechte obere Ecke
und alle
anderen Eintragungen im Teil-Rechteck,
dessen rechte obere Ecke
![]() ist, 0 sind.
Anders formuliert, die Spalten-Nummern
ist, 0 sind.
Anders formuliert, die Spalten-Nummern
![]() der führenden 1'er
in der
der führenden 1'er
in der
![]() -ten Zeile sind streng monoton wachsend.
Durch Abziehen entsprechender Vielfachen von den darüberstehenden Zeilen
können wir weiters erreichen, daß in der Spalte über
-ten Zeile sind streng monoton wachsend.
Durch Abziehen entsprechender Vielfachen von den darüberstehenden Zeilen
können wir weiters erreichen, daß in der Spalte über
![]() ebenfalls lauter 0'er sind.
ebenfalls lauter 0'er sind.
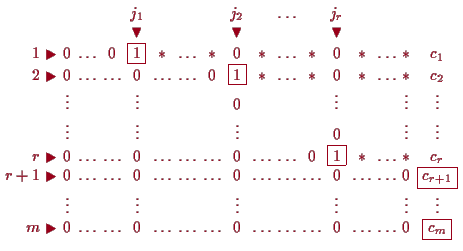
Für die Lösung bedeutet dies nun, daß falls die letzten
![]() Gleichungen
nicht widersprüchlich sind (d.h.
Gleichungen
nicht widersprüchlich sind (d.h.
![]() ist), so können
die
ist), so können
die
![]() Variablen der übrigen Spalten
Variablen der übrigen Spalten
![]() mit
mit
![]() frei gewählt werden
und die anderen
frei gewählt werden
und die anderen
![]() Variablen
Variablen
![]() daraus eindeutig berechnet werden.
daraus eindeutig berechnet werden.
Diese Methode zur Bestimmung der Lösungen eines linearen Gleichungssystems nennt man Gauß'sches Eliminationsverfahren.
11.5 Proposition.
Elementare Zeilenumformungen einer
![]() -Matrix über einem Körper
-Matrix über einem Körper
![]() lassen sich durch Multiplikation von links mit einer
invertierbaren
lassen sich durch Multiplikation von links mit einer
invertierbaren
![]() -Matrix ausdrücken. Wendet man also auf die
erweiterte Matrix eines linearen Gleichungssystems eine beliebige
Abfolge von elementaren Zeilenoperationen an, so erhält man die
erweiterte Matrix eines äquivalenten Systems.
-Matrix ausdrücken. Wendet man also auf die
erweiterte Matrix eines linearen Gleichungssystems eine beliebige
Abfolge von elementaren Zeilenoperationen an, so erhält man die
erweiterte Matrix eines äquivalenten Systems.
Beweis. Es sei
Multiplikation der
![]() -ten Zeile von
-ten Zeile von
![]() mit den Skalar
mit den Skalar
![]() läßt
sich durch Multiplikation von links mit der Matrix, die auf der Diagonale
lauter 1'er hat bis auf die
läßt
sich durch Multiplikation von links mit der Matrix, die auf der Diagonale
lauter 1'er hat bis auf die
![]() -te Stelle wo
-te Stelle wo
![]() und sonst lauter 0'er
als Eintragungen hat. Die zugehörige bijektive lineare Abbildung
und sonst lauter 0'er
als Eintragungen hat. Die zugehörige bijektive lineare Abbildung
![]() wird durch
wird durch
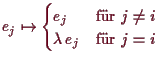
Sei schließlich
![]() und
und
![]() mit
mit
![]() beliebig. Nach (10.7) gibt es eine eindeutige
lineare Abbildung
beliebig. Nach (10.7) gibt es eine eindeutige
lineare Abbildung
![]() , die
, die
![]() und
und
![]() für
für
![]() erfüllt. Für
erfüllt. Für
![]() gilt dann
gilt dann
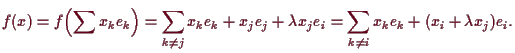
Die Spalten von
![]() erhält man indem man
erhält man indem man
![]() auf die Spalten von
auf die Spalten von
![]() anwendet. Das bedeutet aber, das
Linksmultiplikation mit
anwendet. Das bedeutet aber, das
Linksmultiplikation mit
![]() genau die Zeilenoperation
genau die Zeilenoperation
![]() liefert. Wir müssen also nur noch sehen, daß
liefert. Wir müssen also nur noch sehen, daß
![]() invertierbar, also
invertierbar, also
![]() ein linearer Isomorphismus ist. Sei dazu
ein linearer Isomorphismus ist. Sei dazu
![]() die analoge Abbildung mit
die analoge Abbildung mit
![]() statt
statt
![]() . Nach Definition bildet
sowohl
. Nach Definition bildet
sowohl
![]() als auch
als auch
![]() jedes
jedes
![]() auf sich selbst ab. Da
eine lineare Abbildung durch ihre Werte auf einer Basis eindeutig
bestimmt ist, folgt daraus
auf sich selbst ab. Da
eine lineare Abbildung durch ihre Werte auf einer Basis eindeutig
bestimmt ist, folgt daraus
![]() , also ist
, also ist
![]() ein
linearer Isomorphismus.
ein
linearer Isomorphismus.
[]
Bemerkung.
Natürlich spielt es eine Rolle, in welcher Reihenfolge elementare
Zeilenoperationen durchgeführt werden. Zum Beispiel erhält man
natürlich ein anderes Ergebnis, wenn man erst
![]() und dann
und dann
![]() anwendet, als wenn man erst
anwendet, als wenn man erst
![]() und dann
und dann
![]() anwendet. Bei
Zeilenoperationen, die keine gemeinsamen Zeilen betreffen spielt die
Reihenfolge aber keine Rolle, und wir werden diese Operationen oft in
einem Schritt durchführen um nicht allzu viel aufschreiben zu
müssen. So kann man etwa für fixes
anwendet. Bei
Zeilenoperationen, die keine gemeinsamen Zeilen betreffen spielt die
Reihenfolge aber keine Rolle, und wir werden diese Operationen oft in
einem Schritt durchführen um nicht allzu viel aufschreiben zu
müssen. So kann man etwa für fixes
![]() und verschiedene
und verschiedene
![]() , die auch alle ungleich
, die auch alle ungleich
![]() sind, die Operationen
sind, die Operationen
![]() bis
bis
![]() gleichzeitig durchführen.
gleichzeitig durchführen.
11.6 Invertierbarkeit und Bestimmung der inversen Matrix.
In diesem Abschnitt betrachten wir eine
![]() -Matrix
-Matrix
![]() über
einem Körper
über
einem Körper
![]() . Wir wollen ein explizites Verfahren
entwickeln, das entscheidet, ob die Matrix
. Wir wollen ein explizites Verfahren
entwickeln, das entscheidet, ob die Matrix
![]() invertierbar ist, und
falls ja, die inverse Matrix
invertierbar ist, und
falls ja, die inverse Matrix
![]() explizit bestimmen. Sind
explizit bestimmen. Sind
![]() und
und
![]() invertierbare
invertierbare
![]() -Matrizen, dann ist
-Matrizen, dann ist
![]() invertierbar (und
invertierbar (und
![]() ) nach Satz (2.5). Ist umgekehrt für
eine invertierbare Matrix
) nach Satz (2.5). Ist umgekehrt für
eine invertierbare Matrix
![]() die Matrix
die Matrix
![]() invertierbar, dann ist
invertierbar, dann ist
![]() ebenfalls invertierbar. Insbesondere ändern elementare
Zeilenoperationen nichts an der Invertierbarkeit einer Matrix, denn diese
lassen sich nach (11.5) durch Multiplikation von links mit einer invertierbaren Matrix
ebenfalls invertierbar. Insbesondere ändern elementare
Zeilenoperationen nichts an der Invertierbarkeit einer Matrix, denn diese
lassen sich nach (11.5) durch Multiplikation von links mit einer invertierbaren Matrix
![]() beschreiben. Wenn
wir also wissen wollen, ob eine Matrix
beschreiben. Wenn
wir also wissen wollen, ob eine Matrix
![]() invertierbar ist, dann
können wir
invertierbar ist, dann
können wir
![]() mit Hilfe des Gauß'schen Algorithmus auf
Zeilenstufenform bringen und überprüfen, ob die resultierende Matrix
invertierbar ist. Das ist relativ einfach, und es liefert sogar
einen Algorithmus zur Berechnung der inversen Matrix:
mit Hilfe des Gauß'schen Algorithmus auf
Zeilenstufenform bringen und überprüfen, ob die resultierende Matrix
invertierbar ist. Das ist relativ einfach, und es liefert sogar
einen Algorithmus zur Berechnung der inversen Matrix:
11.7 Theorem.
Ist
![]() eine beliebige invertierbare
eine beliebige invertierbare
![]() -Matrix über einem
Körper
-Matrix über einem
Körper
![]() , dann kann man
, dann kann man
![]() durch eine endliche Folge von
elementaren Zeilenoperationen in die Einheitsmatrix
durch eine endliche Folge von
elementaren Zeilenoperationen in die Einheitsmatrix
![]() umwandeln. Man erhält die inverse Matrix
umwandeln. Man erhält die inverse Matrix
![]() indem man die
dazu nötigen Zeilenoperationen in der selben Reihenfolge auf die
Einheitsmatrix
indem man die
dazu nötigen Zeilenoperationen in der selben Reihenfolge auf die
Einheitsmatrix
![]() anwendet.
anwendet.
Beweis. Sei
Bemerkung.
Beispiele.
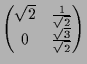
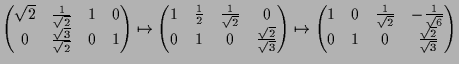
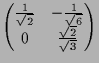
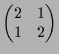
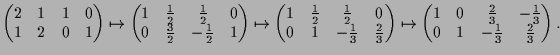
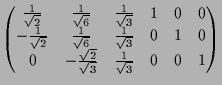 |
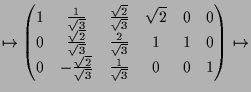 |
|
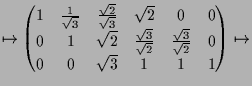 |
||
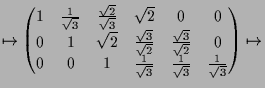 |
||
|
||
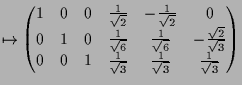 |
 |
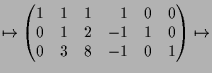 |
|
 |
||
 |
||
 |
11.8 Definition.
Eine lineare Abbildung
![]() heißt regulär,
wenn sie den maximal möglichen Rang
heißt regulär,
wenn sie den maximal möglichen Rang
![]() hat.
hat.
11.9 Lemma.
Der Rang einer Matrix
![]() stimmt mit jenen der auf Zeilenstufenform
transformierten Matrix überein und letzterer ist genau die Anzahl
stimmt mit jenen der auf Zeilenstufenform
transformierten Matrix überein und letzterer ist genau die Anzahl
![]() der von
0 verschiedenen Zeilen.
der von
0 verschiedenen Zeilen.
Beweis. Elementare Zeilenumformungen ändern die Lösungsmenge des (homogenen) Gleichungssystems
Nach (10.21) ist der Rang die maximale Anzahl linear unabhängiger
Spalten.
In der Zeilenstufenform stehen in den Spalten
![]() mit führenden
1'ern in den entsprechenden Zeilen gerade die Einheitsvektoren
mit führenden
1'ern in den entsprechenden Zeilen gerade die Einheitsvektoren
![]() . Diese sind linear unabhängig und alle anderen
Spalten lassen sich als Linearkombination dieser schreiben.
Also ist
. Diese sind linear unabhängig und alle anderen
Spalten lassen sich als Linearkombination dieser schreiben.
Also ist
![]() die maximale Anzahl linearunabhängiger Spalten und somit der
Rang von
die maximale Anzahl linearunabhängiger Spalten und somit der
Rang von
![]() .
[]
.
[]
11.9a Bemerkung.
Der Rang einer Matrix ist ebenso die maximale Anzahl linear
unabhängiger Zeilen, denn die oben angegebenen Operationen ändern
den Zeilenrang nicht und jener der transformierten Matrix
![]() ist gerade
ist gerade
![]() .
Dies folgt mittels (13.15) auch aus
.
Dies folgt mittels (13.15) auch aus
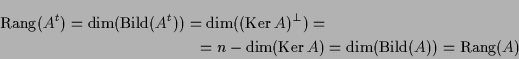
11.10 Folgerung.
Eine lineare Gleichung
![]() ist genau dann lösbar, wenn
der Rang der Matrix
ist genau dann lösbar, wenn
der Rang der Matrix
![]() von
von
![]() gleich jenen der erweiterten Matrix
gleich jenen der erweiterten Matrix
![]() ist.
ist.
Beweis. Es ist
11.11 Proposition.
Es seien
![]() und
und
![]() Vektorräume der Dimension
Vektorräume der Dimension
![]() sowie
sowie
![]() und
und
![]() Basen von diesen. Für
Basen von diesen. Für
![]() sind folgende Aussagen äquivalent:
sind folgende Aussagen äquivalent:
Beweis.
![]() ist (10.5).
ist (10.5).
![]() ist offensichtlich, wegen
ist offensichtlich, wegen
![]() .
.
![]() folgt aus der Dimensionsformel
folgt aus der Dimensionsformel
![]() .
.
![]() , da
, da
![]() und
und
![]() nach (10.16) Isomorphismen
sind.
nach (10.16) Isomorphismen
sind.
![]() gilt da wegen (10.23) und 10.24
die lineare Abbildung
gilt da wegen (10.23) und 10.24
die lineare Abbildung
![]() genau dann invertierbar ist,
wenn die Matrix
genau dann invertierbar ist,
wenn die Matrix
![]() es ist.
es ist.
![]() ist offensichtlich.
[]
ist offensichtlich.
[]
Wir wollen als nächstes kurz eine Anwendung der linearen Algebra
über endlichen Körpern besprechen, nämlich die sogenannten linearen
Codes. Der Einfachheit halber werden wir uns auf den Körper
![]() beschränken und hauptsächlich ein konkretes Beispiel (nämlich
den sogenannten Hemming-(4,7)-Code) besprechen, anstatt die
allgemeine Theorie zu entwickeln.
beschränken und hauptsächlich ein konkretes Beispiel (nämlich
den sogenannten Hemming-(4,7)-Code) besprechen, anstatt die
allgemeine Theorie zu entwickeln.
Bei Codes sollte man nicht an Geheimbotschaften denken, sondern daran,
daß man eine Botschaft übertragen möchte, wobei man damit rechnen
muß, daß bei der Übertragung Fehler auftreten können. Der
Einfachheit halber treffen wir die (ziemlich realistische) Annahme,
daß unsere Botschaft einfach eine Folge von ``Worten'' einer fixen
Länge
![]() in den ``Buchstaben''
in den ``Buchstaben''
![]() ist. Wir können also ein
solches Wort als ein Element
ist. Wir können also ein
solches Wort als ein Element
![]() betrachten. (Bislang wir die Restklassen mit eckigen Klammern angedeutet,
also
betrachten. (Bislang wir die Restklassen mit eckigen Klammern angedeutet,
also
![]() geschrieben. Die jetzige Schreibweise ist aber dadurch gerechtfertigt,
daß
geschrieben. Die jetzige Schreibweise ist aber dadurch gerechtfertigt,
daß
![]() das additiv neutrale und
das additiv neutrale und
![]() das multiplikativ
neutrale Element ist, die wir ja immer mit
0 bzw.
das multiplikativ
neutrale Element ist, die wir ja immer mit
0 bzw.
![]() bezeichnet
haben.) Die einzige Rechenregel in
bezeichnet
haben.) Die einzige Rechenregel in
![]() , die nicht aus den
Eigenschaften der neutralen Elemente folgt ist
, die nicht aus den
Eigenschaften der neutralen Elemente folgt ist
![]() .
.
Wir wollen nun annehmen, daß wir unsere Botschaft auf irgend eine Art und Weise übertragen, und das vereinzelt Fehler auftreten können, also vereinzelt Nullen in Einser und Einser in Nullen verwandelt werden. Wir wollen solche Fehler erkennbar und wenn möglich sogar korrigierbar machen, indem wir zusätzliche Informationen übertragen (in die bei der Übertragung natürlich auch Fehler hinein kommen können). Damit so etwas praktisch nutzbar ist, sollte natürlich die Codierung (also das Hinzufügen der zusätzlichen Information) und die Decodierung (also das Zurückgewinnen der ursprünglichen Information) möglichst einfach sein.
Eine einfache Methode in dieser Richtung ist die Übertragung eines
zusätzlichen Prüf- oder Paritätsbits. Man macht einfach aus einem
Wort
![]() der Länge
der Länge
![]() ein Wort der Länge
ein Wort der Länge
![]() , indem
man
, indem
man
![]() so wählt, daß in dem Wort
so wählt, daß in dem Wort
![]() eine
gerade Anzahl von Einsen vorkommt, d.h.
eine
gerade Anzahl von Einsen vorkommt, d.h.
![]() (in
(in
![]() !). Empfängt man ein Wort der Länge
!). Empfängt man ein Wort der Länge
![]() , dann bildet man
, dann bildet man
![]() . Ist diese Summe gleich Null, dann nimmt man
einfach die ersten
. Ist diese Summe gleich Null, dann nimmt man
einfach die ersten
![]() Elemente als übertragenes Wort. Ist die Summe
gleich Eins, dann weiß man, daß in der Übertragung ein Fehler
aufgetreten ist (aber nicht an welcher Stelle). Treten zwei Fehler
auf, dann kann man das mit dieser Methode nicht mehr erkennen. Man
kann diese Methode so interpretieren, daß man auf die Datenworte aus
Elemente als übertragenes Wort. Ist die Summe
gleich Eins, dann weiß man, daß in der Übertragung ein Fehler
aufgetreten ist (aber nicht an welcher Stelle). Treten zwei Fehler
auf, dann kann man das mit dieser Methode nicht mehr erkennen. Man
kann diese Methode so interpretieren, daß man auf die Datenworte aus
![]() zunächst eine lineare Abbildung
zunächst eine lineare Abbildung
![]() (die das Hinzufügen des Prüfbits beschreibt)
anwendet, dann das Bild überträgt. Dann kann man mit
einer linearen Abbildung
(die das Hinzufügen des Prüfbits beschreibt)
anwendet, dann das Bild überträgt. Dann kann man mit
einer linearen Abbildung
![]() (dem Verifikationstest)
feststellen ob ein
Fehler aufgetreten ist, und falls nicht das ursprüngliche Wort durch
eine lineare Abbildung
(dem Verifikationstest)
feststellen ob ein
Fehler aufgetreten ist, und falls nicht das ursprüngliche Wort durch
eine lineare Abbildung
![]() (der Rekonstruktion)
rekonstruieren.
(der Rekonstruktion)
rekonstruieren.
Wichtig für die Qualität eines Codes ist nicht die lineare
Abbildung, die zum Bilden der Codeworte verwendet wird, sondern nur
ihr Bild. Deshalb definiert man einen linearen
![]() -Code über
-Code über
![]() als einen
als einen
![]() -dimensionalen Teilraum
-dimensionalen Teilraum
![]() von
von
![]() . Wir wollen nun einen (sehr guten) linearen
. Wir wollen nun einen (sehr guten) linearen
![]() -Code, den
sogenannten Hemming
-Code, den
sogenannten Hemming
![]() -Code beschreiben, bei dem mit 3
Prüfbits bis zu
-Code beschreiben, bei dem mit 3
Prüfbits bis zu
![]() Fehler sicher erkannt und Einzelfehler sicher
korrigiert werden können. (Warum gerade die Kombination
Fehler sicher erkannt und Einzelfehler sicher
korrigiert werden können. (Warum gerade die Kombination
![]() günstig ist, werden wir im Verlauf der Konstruktion sehen.)
günstig ist, werden wir im Verlauf der Konstruktion sehen.)
Wir suchen also einen
![]() -dimensionalen Teilraum
-dimensionalen Teilraum
![]() von
von
![]() , dessen Element die gültigen Codeworte sind. Eine
einfache Methode, so einen Teilraum anzugeben, ist als Kern einer
surjektiven linearen Abbildung
, dessen Element die gültigen Codeworte sind. Eine
einfache Methode, so einen Teilraum anzugeben, ist als Kern einer
surjektiven linearen Abbildung
![]() , deren
zugehörige Matrix
, deren
zugehörige Matrix
![]() die Kontrollmatrix des Codes
heißt. Somit ist ein (empfangenes) Codewort
die Kontrollmatrix des Codes
heißt. Somit ist ein (empfangenes) Codewort
![]() genau dann gültig,
wenn
genau dann gültig,
wenn
![]() gilt. Das Auftreten eines Fehlers in der Übertragung kann
man so interpretieren, daß zu einem gültigen Codewort
gilt. Das Auftreten eines Fehlers in der Übertragung kann
man so interpretieren, daß zu einem gültigen Codewort
![]() ein Fehlerwort
ein Fehlerwort
![]() addiert wird. (In
addiert wird. (In
![]() entspricht ja Addition
von
entspricht ja Addition
von
![]() genau dem Vertauschen von
0 und
genau dem Vertauschen von
0 und
![]() .) Die Anzahl der
Übertragungsfehler ist genau die Anzahl der Einsen in
.) Die Anzahl der
Übertragungsfehler ist genau die Anzahl der Einsen in
![]() . Wegen der
Linearität gilt nun
. Wegen der
Linearität gilt nun
![]() , also können Fehler genau dann
erkannt werden, wenn die Fehlerworte nicht im Kern von
, also können Fehler genau dann
erkannt werden, wenn die Fehlerworte nicht im Kern von
![]() liegen. Wollen wir also Einzelfehler erkennen, dann muß zumindest
liegen. Wollen wir also Einzelfehler erkennen, dann muß zumindest
![]() für
für
![]() gelten.
gelten.
Wir wollen aber Einzelfehler nicht nur erkennen, sondern sogar
korrigieren können. Um das zu tun, müssen wir die Einzelfehler von
einander unterscheiden können, also muß
![]() für
für
![]() gelten. Dies läßt uns für
gelten. Dies läßt uns für
![]() aber im Wesentlichen nur noch eine
Möglichkeit, weil
aber im Wesentlichen nur noch eine
Möglichkeit, weil
![]() genau
genau
![]() Elemente, also genau
Elemente, also genau
![]() Elemente außer Null hat. Wir wählen also
Elemente außer Null hat. Wir wählen also
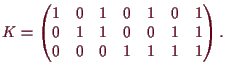
Somit gehen wir also folgendermaßen vor: Empfangen wir ein Wort
![]() ,
dann bilden wir
,
dann bilden wir
![]() . Ist das gleich Null, dann ist kein (erkennbarer)
Übertragungsfehler aufgetreten, und
. Ist das gleich Null, dann ist kein (erkennbarer)
Übertragungsfehler aufgetreten, und
![]() ist das richtige
Codewort. Ist
ist das richtige
Codewort. Ist
![]() , dann ist sicher ein Übertragungsfehler
aufgetreten. War das ein Einzelfehler (die wahrscheinlichste
Möglichkeit) dann erhält man das ursprüngliche Codewort, indem man
, dann ist sicher ein Übertragungsfehler
aufgetreten. War das ein Einzelfehler (die wahrscheinlichste
Möglichkeit) dann erhält man das ursprüngliche Codewort, indem man
![]() als Binärzahl
als Binärzahl
![]() interpretiert und dann die
interpretiert und dann die
![]() -te Eintragung
von
-te Eintragung
von
![]() ändert (also
ändert (also
![]() bildet).
bildet).
Nun wollen wir noch eine konkrete Codierung angeben, also eine lineare
Abbildung
![]() , deren zugehörige Matrix die Generatormatrix
, deren zugehörige Matrix die Generatormatrix
![]() des Codes heißt. Die einfachste Möglichkeit
wäre natürlich, an ein Wort
des Codes heißt. Die einfachste Möglichkeit
wäre natürlich, an ein Wort
![]() einfach drei geeignete
Prüfbits
einfach drei geeignete
Prüfbits
![]() anzuhängen. Um das zu realisieren müßten
die ersten 4 Zeilen der
anzuhängen. Um das zu realisieren müßten
die ersten 4 Zeilen der
![]() -Matrix
-Matrix
![]() die
die
![]() -Einheitsmatrix
-Einheitsmatrix
![]() bilden. Das stellt auch sicher, daß
bilden. Das stellt auch sicher, daß
![]() einer injektiven linearen Abbildung entspricht, also genügt es
zusätzlich sicher zu stellen, daß
einer injektiven linearen Abbildung entspricht, also genügt es
zusätzlich sicher zu stellen, daß
![]() gilt, denn dann liefert
gilt, denn dann liefert
![]() aus Dimensionsgründen einen linearen Isomorphismus
aus Dimensionsgründen einen linearen Isomorphismus
![]() . Nun verifiziert man leicht durch Lösen eines
linearen Gleichungssystems, daß die beiden Bedingungen
. Nun verifiziert man leicht durch Lösen eines
linearen Gleichungssystems, daß die beiden Bedingungen
![]() eindeutig
festlegen. Bestimmt man
eindeutig
festlegen. Bestimmt man
![]() explizit, dann sieht man, daß die
Prüfbits gegeben sind durch
explizit, dann sieht man, daß die
Prüfbits gegeben sind durch
![]() ,
,
![]() und
und
![]() .
.
Beispiel.
Nehmen wir an, daß ursprüngliche Datenwort
ist
![]() . Nach der Vorschrift zum Bilden der Prüfbits wird das
zu
. Nach der Vorschrift zum Bilden der Prüfbits wird das
zu
![]() kodiert. Wird dieses Codewort korrekt
übertragen, dann erhält man
kodiert. Wird dieses Codewort korrekt
übertragen, dann erhält man
![]() , und gewinnt das ursprüngliche
Wort
, und gewinnt das ursprüngliche
Wort
![]() als die ersten vier Stellen. Tritt etwa an der
zweiten Stelle ein Fehler auf, dann empfangen wir statt
als die ersten vier Stellen. Tritt etwa an der
zweiten Stelle ein Fehler auf, dann empfangen wir statt
![]() das Wort
das Wort
![]() . Nachrechnen ergibt
. Nachrechnen ergibt
![]() . Also sehen
wir, daß ein Fehler aufgetreten ist, und zwar vermutlich an der
zweiten Stelle. Also sollte das übertragene Wort
. Also sehen
wir, daß ein Fehler aufgetreten ist, und zwar vermutlich an der
zweiten Stelle. Also sollte das übertragene Wort
![]() sein, dessen erste vier Stellen das richtige Datenwort
sein, dessen erste vier Stellen das richtige Datenwort
![]() liefern. Nehmen wir nun an, daß zwei Übertragungsfehler auftreten,
etwa an der zweiten und der letzten Stelle. Dann empfangen wir das
Wort
liefern. Nehmen wir nun an, daß zwei Übertragungsfehler auftreten,
etwa an der zweiten und der letzten Stelle. Dann empfangen wir das
Wort
![]() und
und
![]() . Wir stellen also
(richtigerweise) fest, daß ein Übertragungsfehler aufgetreten ist,
der wahrscheinlichste Übertragungsfehler wäre aber eine Änderung in
der fünften Stelle (also einem Prüfbit), und wir würden
(fälschlicherweise) vermuten, daß das ursprüngliche Wort
. Wir stellen also
(richtigerweise) fest, daß ein Übertragungsfehler aufgetreten ist,
der wahrscheinlichste Übertragungsfehler wäre aber eine Änderung in
der fünften Stelle (also einem Prüfbit), und wir würden
(fälschlicherweise) vermuten, daß das ursprüngliche Wort
![]() war.
war.